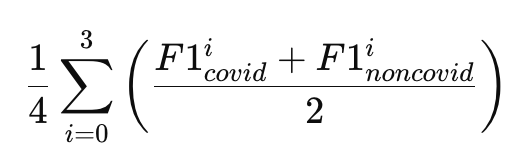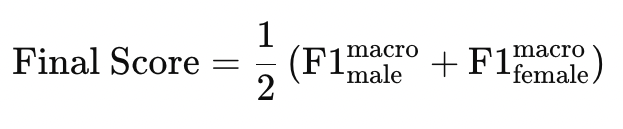A main target of the Workshop is to present and evaluate novel approaches for predictive modeling of big medical image datasets, focusing on deep learning models, on transparent and human-centered integration of Generative AI and Large Models (such as LLMs, VLMs) in Health Services, creating trust among citizens. It addresses key challenges at the intersection of computer vision and healthcare AI, including multidisease diagnosis, model explainability, fairness, domain adaptation, and continual learning. Given the increasing interest in trustworthy AI, interpretable deep learning models, and the responsible deployment of AI in sensitive applications, this workshop will foster discussions on critical advancements shaping the future of AI in medical imaging. The Workshop is organised in compliance with the PHAROS AI Factory, which is one of the first seven AI Factories selected and funded by the European Union. This ensures that the workshop’s topics have real-world applicability and a strong foundation in cutting-edge research.
A Competition is also organized, which is split into two Challenges (the Multi-Source Covid-19 Detection Challenge and the Fair Disease Diagnosis Challenge) offering two large databases and letting research groups test and compare their state-of-the-art AI approaches.
The PHAROS-AFE-AIMI Workshop is the fifth in the AI-MIA series of Workshops held at CVPR 2024 and IEEE ICASSP 2023, ECCV 2022 and ICCV 2021 Conferences.
For any requests or enquiries regarding the Workshop, please contact: stefanos@cs.ntua.gr.